Mapping the Unspoken: How Meta Built an AI to Unlock Tribal Knowledge in Massive Codebases
Introduction
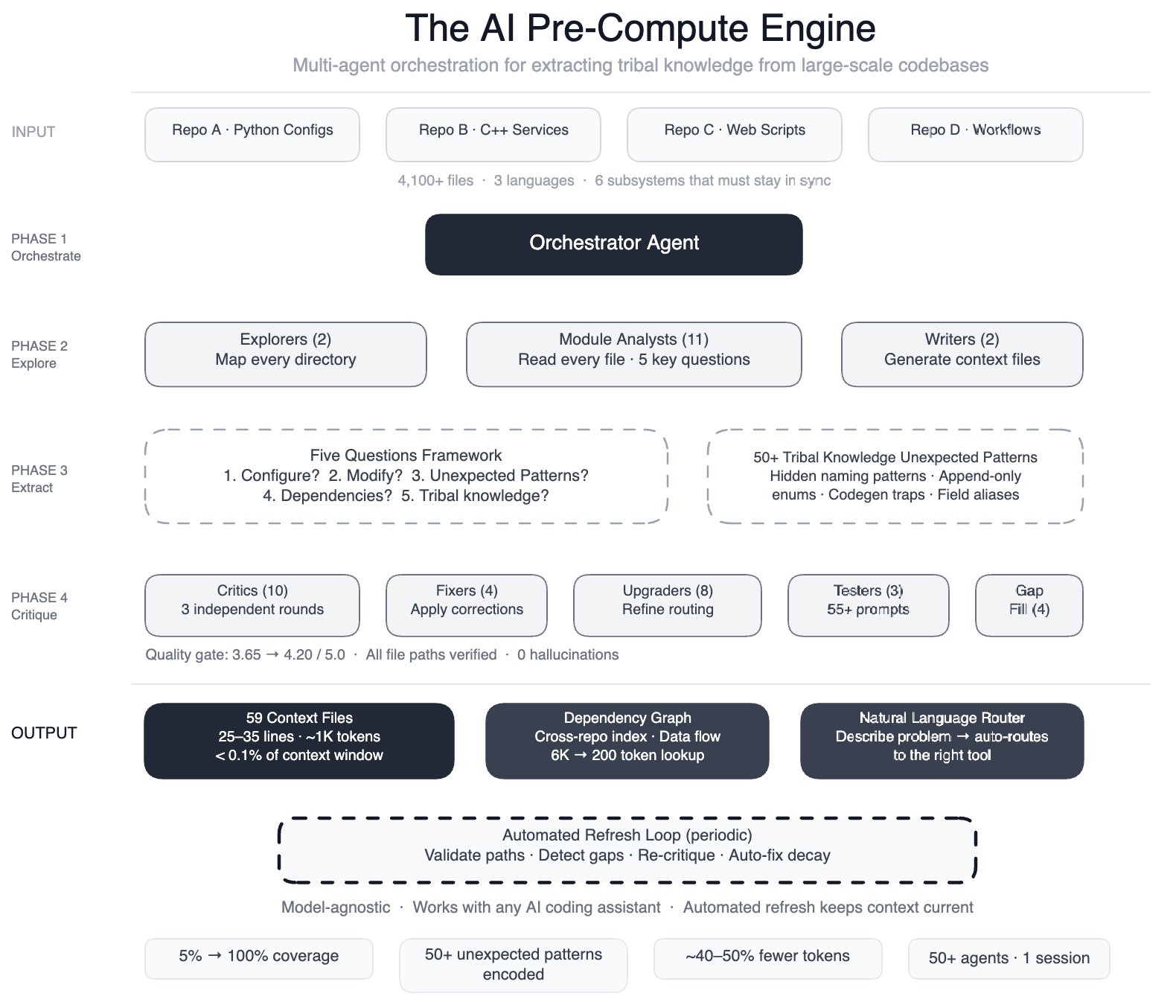
AI coding assistants have become invaluable tools for developers, but they are only as effective as their comprehension of the codebase they operate on. When Meta attempted to deploy AI agents across one of its large-scale data processing pipelines—spanning four repositories, three programming languages, and over 4,100 files—the results were disappointing. The agents struggled to make meaningful edits quickly, often guessing incorrectly or producing code that compiled but behaved unpredictably.

The root cause was clear: the AI lacked tribal knowledge—the unwritten rules, design decisions, and subtle dependencies that human engineers internalize over years. To bridge this gap, Meta engineered a pre-compute engine: a swarm of more than 50 specialized AI agents that systematically read every file and generated 59 concise context files. These files now serve as structured navigation guides for 100% of the code modules (up from just 5%), covering all 4,100+ files across three repositories. Additionally, the system documented over 50 “non-obvious patterns”—implicit design choices and relationships not immediately visible in the code itself. Early tests indicate a 40% reduction in the number of tool calls per task required by AI agents. Because the knowledge layer is model-agnostic, it works seamlessly with leading AI models.
The system is also self-maintaining. Automated jobs run every few weeks to validate file paths, detect coverage gaps, re-run quality critiques, and automatically fix stale references. In this architecture, the AI isn’t just a consumer of the infrastructure—it’s the engine that keeps it running.
The Problem: AI Tools Without a Map
Meta’s pipeline operates as config-as-code, combining Python configurations, C++ services, and Hack automation scripts that work together across multiple repositories. A single data field onboarding process touches six subsystems: configuration registries, routing logic, DAG composition, validation rules, C++ code generation, and automation scripts—all of which must stay perfectly synchronized.
Meta had previously built AI-powered systems for operational tasks—scanning dashboards, pattern-matching against historical incidents, and suggesting mitigations. Those worked well. But when they tried to extend the same approach to development tasks, the system failed. The AI had no mental map of the codebase. It didn’t know, for instance, that two configuration modes use different field names for the same operation (swap them and you get silent wrong output), or that dozens of “deprecated” enum values must never be removed because serialization compatibility depends on them.
Without this context, the agents would guess, explore, guess again, and often produce code that compiled but was subtly wrong—creating hidden technical debt.
The Approach: Teach the Agents Before They Explore
Meta’s solution was to build a structured knowledge extraction pipeline using a large-context-window model and task orchestration. The process unfolded in distinct phases, each handled by specialized AI agents:
- Two explorer agents mapped the overall codebase structure.
- 11 module analysts read every file and answered five key questions about intent, dependencies, and hidden constraints.
- Two writers generated the 59 context files from the analysts’ findings.
- 10+ critic passes ran three independent rounds of quality review.
- Four fixers applied corrections based on critic feedback.
- Eight upgraders refined the routing layer to ensure context files were easy to navigate.
- Three prompt testers validated 55+ queries across five different user personas.
- Four gap-fillers ensured no directory was left uncovered.
- Three final critics ran integration tests on the entire knowledge base.
This orchestrated swarm—over 50 specialized tasks—ran in a single session, creating a comprehensive, model-agnostic knowledge layer that any AI agent could consume.
Self-Maintaining Knowledge: The AI That Repairs Itself
The knowledge layer is not a one-time artifact. Every few weeks, automated validation jobs run across the entire system. They check that file paths still exist, detect coverage gaps where new code has been added, re-run quality critics on existing context files, and auto-fix stale references. This ensures that the knowledge remains accurate even as the codebase evolves.
The result is a virtuous cycle: the AI that was originally the consumer of the knowledge is now the engine that generates and maintains it. This self-repair capability dramatically reduces the manual overhead of keeping documentation alive.
Impact and Future Directions
The impact has been significant. By providing AI agents with a structured map of tribal knowledge, Meta achieved a 40% reduction in tool calls per task—meaning agents reach correct solutions faster and with fewer dead ends. The system covers 100% of code modules across the three primary repositories, up from a mere 5% before. The documented non-obvious patterns have also proven valuable for human engineers onboarding to the pipeline.
Because the context files are model-agnostic, they can be reused with any mainstream AI coding assistant. Meta plans to expand this approach to other large-scale pipelines and is exploring ways to generalize the knowledge extraction process so it can be applied to diverse codebases.
In a world where AI agents are increasingly tasked with software maintenance and evolution, the ability to codify and serve tribal knowledge may be the key to unlocking their full potential. Meta’s experiment shows that teaching the AI before it starts exploring is far more effective than letting it stumble in the dark.